













数字人能力采购项目
方案
目
录
一、 整体系统设计方案
1
(一) 项目需求理解
1
(二) 数字人系统架构
2
(三) 数字人设计方案
2
1. 数字人造型方案
3
2. 原画建模
3
3. 基于图像的建模技术
4
4. 相机阵列扫描
4
5. 服装设计
5
(四) 数字人动作方案
6
1. 骨骼搭建绑定
6
2. 动作设计
7
3. 数字人表情方案
8
4. 面部参数绑定
8
5. 表情捕捉
9
6. 实时渲染与后处理
9
7. AI 驱动算法
10
8. 其他配套要求
10
(五) 数字人能力方案
11
1. 多模态交互
14
2. 唇形渲染/动作生成
14
(1) blendshape 驱动口型方法
14
(2) 音素驱动口型方法
15
(3) 动作驱动
15
(4) 语音播报视频生成驱动
16
(5) 对话配置
16
(6) 动作配置
18
(7) 图片配置
19
3. 接口方案
19
(1) 接口规范和集成方法
20
(2) 端侧渲染 SDK
21
(3) 虚拟人语音对话 pipeline
22
(4) 虚拟人文本对话 pipeline
24
(5) WEB Demo-React
26
(6) Android Kotlin Demo
27
(7)
IOS WKWebView Demo import UIKit
27
(8) RTC 交互 SDK
29
4. 云端部署方案
32
(1) 应用容器化
33
(2) 数据持久化
33
(3) 安全性与访问控制
33
(4) 监控与日志
33
(5) 维护与支持
33
5. 数字人技术方案
34
(1) 终端适配
34
(2) 扩展性
34
(3) 可靠性
34
(4) 业务连续性
35
(六) 项目交付方案
36
1. 项目交付实施管理规范
36
2. 项目组织架构
49
(1) 团队配置
49
(2) 项目团队管理
49
3. 项目测试方案
50
(1) 系统测试技术
50
(2) 项目测试的工作流程规范
62
(3) 测试计划
63
(4) 系统集成测试
65
(5) 系统性能测试
65
(6) 回归测试
66
(7) 验收测试
66
(8) 项目测试总结
67
4. 项目实施进度计划
67
5. 质量保障措施
68
6. 拟提供的技术文档
69
(七) 系统部署方案
71
1. 部署架构
71
(1) 平台系统部署
71
(2) 部署架构描述
71
(3) 微服务容器化部署
72
2. 可扩展性
73
(1) 横向扩展
73
(2) 纵向扩展
74
3. 服务连续性
74
4. 与外围系统对接方案可行性
74
5. 系统访问控制策略
75
6. 系统监控
76
7. 数据安全性
77
二、 项目总体服务方案
79
(一) 技术支持服务
79
1. 服务渠道
79
(1) 现场支持
79
(2) 远程支持
80
(3) 电话支持
80
2. 风险管理及风险应对
82
(1) 20.10.0.1风险基础
84
(2) 风险管理基本原则
85
(3) 风险管理中的关键概念
87
(4) 风险管理计划
91
(5) 风险管理过程
92
3. 项目生命周期中的集成
120
4. 服务质量保障
121
(1) 服务保障
121
5. 服务支撑与响应
122
(1) 服务宗旨
122
(2) 服务流程
122
(3) 投诉受理机制
123
(4) 诊断故障并提交故障诊断报告
123
(5) 制定系统维护和故障恢复的实施计划
123
(6) 管理、监督维护计划的实施
123
(7) 确认维护工作完成并提交维护报告
123
(8) 提交成果
124
(9) 服务验收
124
(10) 服务范围和内容
124
(11) 技术咨询服务
124
(12) 系统维护与技术支持服务
124
(13) 培训服务
125
(14) 系统测试服务
125
(15) 软件升级服务
125
(16) 安全预警服务
125
(17) 服务阶段划分
126
6. 应急处理方案
126
(1) 应急处理机构和职责
126
(2) 应急处理工作措施
127
7. 技术培训及人员服务安排
129
(1) 人员培训
129
(2) 培训内容
129
(3) 培训方式
131
(4) 效果保障
131
8. 售后服务优势
132
(1) 全面快速的技术服务中心
132
(2) 经验丰富的客户服务小组
132
(3) 完善的售后服务体系
132
(4) 规范化的客户需求记录、缺陷跟踪及专人管理
132
(5) 知识产权归属承诺
132
整体系统设计方案
项目需求理解
本期项目的建设将引入AI数字人能力,用于服务IPTV
、天翼云盒、悦me等天翼高清
平台,从而满足大屏AI能力提升及创新内容运营的需求,也同步培养用户以语音方式操控
机顶盒的习惯。同时本期项目中建设的数字人能力还可以直接灵活的复用到数字生活公司其他产品,如天翼中屏等。
通过前期的沟通和交流,在本期项目中将完成如下建设目标:
本期项目所建设的3D数字人可以在中国电信安卓9以上机顶盒集成并实时渲染动作、
表情和唇形,唇形需与语音播报同步、内容一致;从而在项目上提供数字人视频、
GIF文件,在不具备实时渲染条件的安卓4.4机顶盒等设备上对3D数字人进行平替。
本期项目所建设的3D数字人有至少6套服装、
6种表情、
20个动作,同时提供的3D数字人SDK能力有API接口能够对服装、表情、动作进行控制,数字人视频、
GIF文件需同样满足
上述服装、表情、动作要求。
本期项目所建设的数字人能力能够复用到数字生活公司其他产品线(如天翼中屏等
)
、
集团内各省公司以及生态合作伙伴的产品上。
另外,在本期项目中,我司将满足如下项目要求:
打造一位仿真人年轻女性,同时提供年轻女性的仿真人三视图,同步我司将完成3D数字人模型设计和制作,
3D数字人具备至少6套服装:工装、休闲装、裙装各1套以及
传统节日服装3套,同时3D数字人的面数不低于20W。
在动作上,针对定制的数字人动作,将设计待机、打招呼、聆听等至少20个动作,动作包含姿态、手势的配套(
在项目初期先交付以下10个动作:
待机:站立,手垂放身体两侧,手和头无规则小幅度移动
打招呼:歪头,一只手招手,然后手放下
聆听:身体前倾,手放在耳朵旁,然后手放下
说话:单手做介绍的姿势,然后手放下
思考:偏头,一只手拖着另一只手,手停留在下巴,身体微晃,然后手
放下
介绍:双手张开,然后手放下
出现:手背在身后,垫脚从侧面走出到正中间,然后手垂放身体两侧
摇头:小幅度摇头,然后回归待机状态的动作
活动身体:晃动身体,手、胳膊跟着晃动
摸头发:一只手撸下头发,然后手放下
在项目过程中,我司将再设计除上述10个数字人动作外的至少10个动作。所有动作均需根据用户要求,每个动作细节应调整至用户满意为止。
在数字人的表情上,我司将设计数字人面部表情,提供数字人包括但不限于高兴、悲伤、惊讶、平静等在内的至少6个表情。
除以上内容外,我司还将根据客户的运营需求,提供上述服装、表情、动作任意组合的数字人视频、GIF文件。
数字人系统架构
小冰
AI
框架已孵化出数以千万计的虚拟人,其中为企业打造的虚拟员工和虚拟专家的
完整产品线,已经成功赋能金融、智能车机、零售、体育、纺织、地产、文旅等十多个垂直 领域的客户的多个业务场景。
小冰从2019年即开始进行虚拟数字人的技术探索和不同行业的商业化落地,交付了大
量的高质量虚拟数字员工项目,小冰团队拥有虚拟数字人定制的标准实施方法
SOP
,以及大
量的实践经验积累。
项目开发包括本地程序与云端服务两部分,本地程序主要包括语音处理、交互控制、图
形渲染等。云端服务主要包括语音识别、语音合成、对话系统、表情生成、二次开发接口等。 系统架构图如下:
数字人设计方案
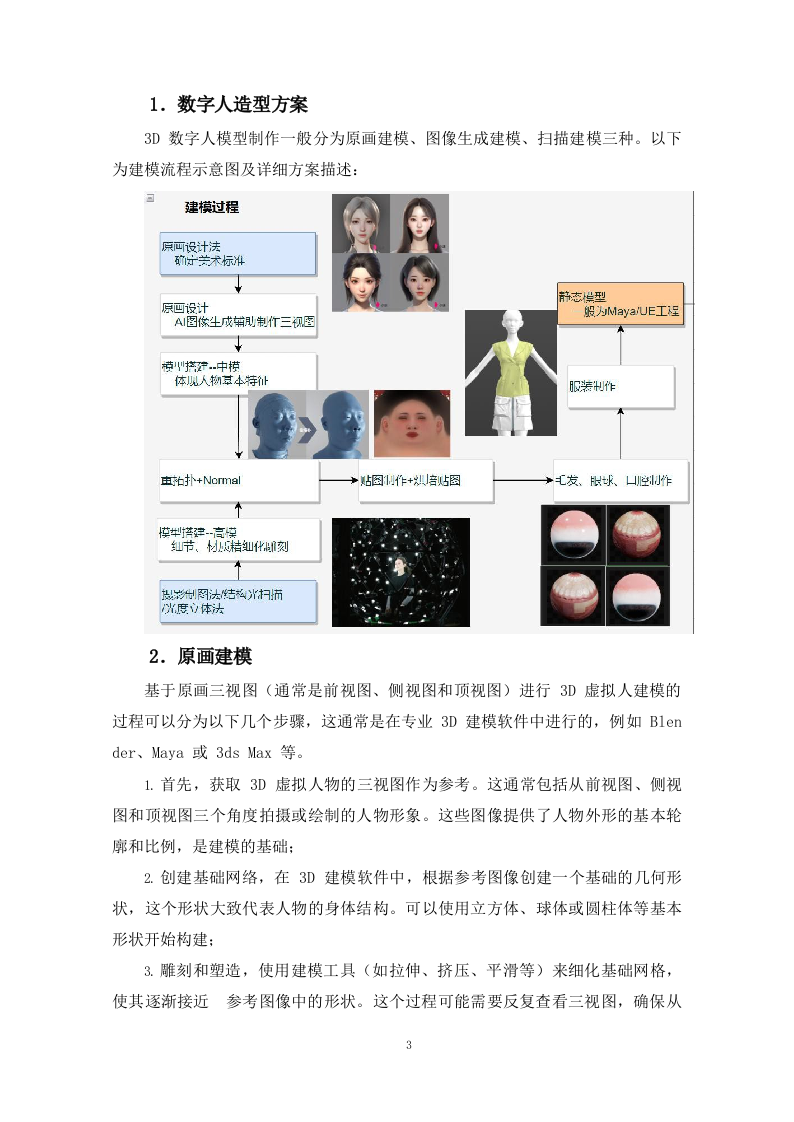
数字人造型方案
3D
数字人模型制作一般分为原画建模、图像生成建模、扫描建模三种。以下为建模流
程示意图及详细方案描述:
原画建模
基于原画三视图(通常是前视图、侧视图和顶视图)
进行
3D
虚拟人建模的过程可以分
为以下几个步骤,这通常是在专业
3D
建模软件中进行的,例如
Blender
、
Maya
或
3ds Max
等。
首先,获取
3D
虚拟人物的三视图作为参考。这通常包括从前视图、侧视图和顶视图三
个角度拍摄或绘制的人物形象。这些图像提供了人物外形的基本轮廓和比例,是建模
的基础;
创建基础网络,在
3D
建模软件中,根据参考图像创建一个基础的几何形状,这个形状
大致代表人物的身体结构。可以使用立方体、球体或圆柱体等基本形状开始构建;
雕刻和塑造,使用建模工具
(
如拉伸、挤压、平滑等
)
来细化基础网格,使其逐渐接近
参考图像中的形状。这个过程可能需要反复查看三视图,确保从各个角度看模型都是
准确无误的;
细调与修正,添加更多的细节,如面部特征、肌肉线条、衣服纹理等。细节的添加同样需要参照三视图来保持一致性;
UV
展开与贴图,完成几何建模后,需要将模型表面“展开”成2D平面,以便为模型添加纹理。UV
映射是指将3D模型的表面投影到一个2D平面上,然后在这个平面上绘制纹理或者贴图,最后将纹理应用回 3D 模型;
材质与光照,定义好纹理之后,还需要为模型设置材质属性
(
如光滑度、反射率等
)
以及光照效果,使得模型在渲染时看起来更加真实。
基于图像的建模技术
是指通过若干幅二维图像,来恢复图像或场景的三维结构,人脸三维重建的研究已经有几十年的历史。
基于人脸图像的三维重建方法非常多,常见的包括立体匹配,
Str
u
ctu
r
e
Fr
o
m
Mot
i
on
(简
称
SfM),Shape from Shading
(简称
sfs
),三维可变形人脸模型
(3DMM),本文就重点讲述3D Morphable models
(简称
3DMM),其相关的传统方法和深度学习方法都有较多的研究。
3DMM
,即三维可变形人脸模型,是一个通用的三维人脸模型,用固定的点数来表示人脸。它的核心思想就是人脸可以在三维空间中进行一一匹配,并且可以由其他许多幅人脸正交基
加权线性相加而来。
当需要基于照片生成虚拟内容时,一类做法是将通用人脸模型迁移至该照片上,形成虚拟形象;另一类先将真人照片中的眼型、发型等元素进行分类,再与预先设置的动漫元素进行匹配,最终生成动漫式的虚拟形象。
相机阵列扫描
通过多个角度的照片,通过分析不同角度的照片逆向计算出照相机的三维坐标,对比照片中相同细节计算出每个象素的深度从而建立三维点云,然后进一步计算出网格。由于几何是由照片推算出来的,照片可以像投影仪一样从相机的位置准确映射到网格上。
这样做有三大好处:
1
. 瞬间捕捉,矩阵所有相机同步拍照;
2
. 照片贴图有丰富的材质纹理,更加真实;3. 贴图和几何完全吻合,避免手工贴图造成错位。
实现步骤:
使用上百台相机进行
360
度的环绕拍摄,构建三维模型,基于模型进行数据的处理,然
后转化成可以编辑的格式,再去进行相关的贴图、绑定动画等操作。
利用了不同图片之间的相同特征点来进行 3D 空间的重建。因此,照片的分辨率,相机内外部参数的控制,人脸光线的均匀程度等因素都会影响到最终的模型质量,需要一个相对理想的拍摄环境来进行拍摄。
服装设计
步骤一:服装设计
概念设计:根据数字人的风格、场景需求和主题,设计衣服款式、颜色和材质。
2D
草图:绘制衣服的
2D
草图,明确设计细节和比例。步骤二:3D
建模与纹理贴图
建模:使用
3D
建模软件根据
2D
草图创建衣服的
3D
模型。包括衣服的褶皱、层次感
和材质特性。
纹理贴图:为衣服模型添加纹理贴图,包括颜色、图案和材质纹理等,以增强视觉
效果。
步骤三:衣服与数字人融合
骨骼绑定:将衣服模型与数字人的骨骼进行绑定,确保衣服能够随着数字人的动作
而自然变形。
动画测试:为数字人添加一些基本动作,测试衣服的适配性和动态效果。
数字人动作方案
骨骼搭建绑定
骨骼、肌肉与模型的绑定过程,目的是便于进行模型驱动。
1、骨骼数:骨骼决定体型和脸型和动作运动规律,在建模绑定时,创建的骨骼越多,模型表现出的动作/表情就越多,自然度也越高。
2
、绑定
Blender Shape
数量;
Blend Shape
用于补充细微肌肉细节,辅助骨骼形变,
构造表情变化。绑定的
Blender Shape
数量越多,模型表情越逼真。目前业内常用的苹果ARKit
2
规范需要
52 blendshapes。
3、绑定表情纹理数量;表情纹理主要用于描述皮肤在表情比较大、皮肤褶皱比较深的
时候的形态。主要用来实现皮肤褶皱、肌肉形态。表情纹理会用到大量的纹理数,因此对于带宽和渲染都会造成一定压力,目前移动端渲染是没有表情纹理的。
动作设计
针对动作的新增部分,将根据和用户讨论,提供动作设计方案,确定后进行相应的动作 数据采集和训练、绑定等工作。
步骤一:动作捕捉
使用动作捕捉设备捕捉真人的动作,并转化为数字人的动作数据。
使用动画软件手动为数字人设计动作,包括行走、奔跑、跳跃、挥手等。
动作捕捉示意图
步骤二:动作调整与优化
根据需要调整动作的速度、力度和流畅度,确保动作符合数字人的性格和场景需求。
优化动作的关键帧,使动作更加自然和逼真。 步骤三:动作集成与测试
将设计好的动作集成到数字人资产中,确保它们能够在不同的场景和情境下无缝切
换。
进行全面的测试,包括单个动作的测试、连续动作的测试以及与其他元素的交互测
试等。
通过以上步骤,可以实现对
3D
数字人资产的全面延展设计,这些设计不仅丰富了数字
人的形象,还提高了其功能性和实用性。
数字人表情方案
3D 数字人的表情是通过一系列技术和艺术手段在三维空间中表现出来的。
首先基于计算驱动表情的技术实现方案主要依赖与对面部的骨骼和形态键绑定,由算法产生骨骼动作系数和形态键系数,进而在渲染器中应用这些绑定和系数,逐帧渲染为表情画面。驱动算法的训练需要使用到基于面部捕捉的表情数据,之后基于时序对表情数据进行特征提取。
面部参数绑定
面部结构:3D
建模软件用于创建数字人的头部模型,包括皮肤、肌肉等层次。
骨骼绑定:在
3
D
模型中添加面部骨骼(
rig
g
ing
)
,这些骨骼模仿真实人脸的肌肉
结构,可以控制模型的变形。
控制器:创建一系列的滑块、旋钮或者其他类型的
UI
元素,这些控制器可以让艺
术家手动调整面部各部分的位置,以产生不同的表情。
参数化表达:通过调整控制器的数值,改变骨骼位置,进而带动面部网格的变化,形成特定的表情。
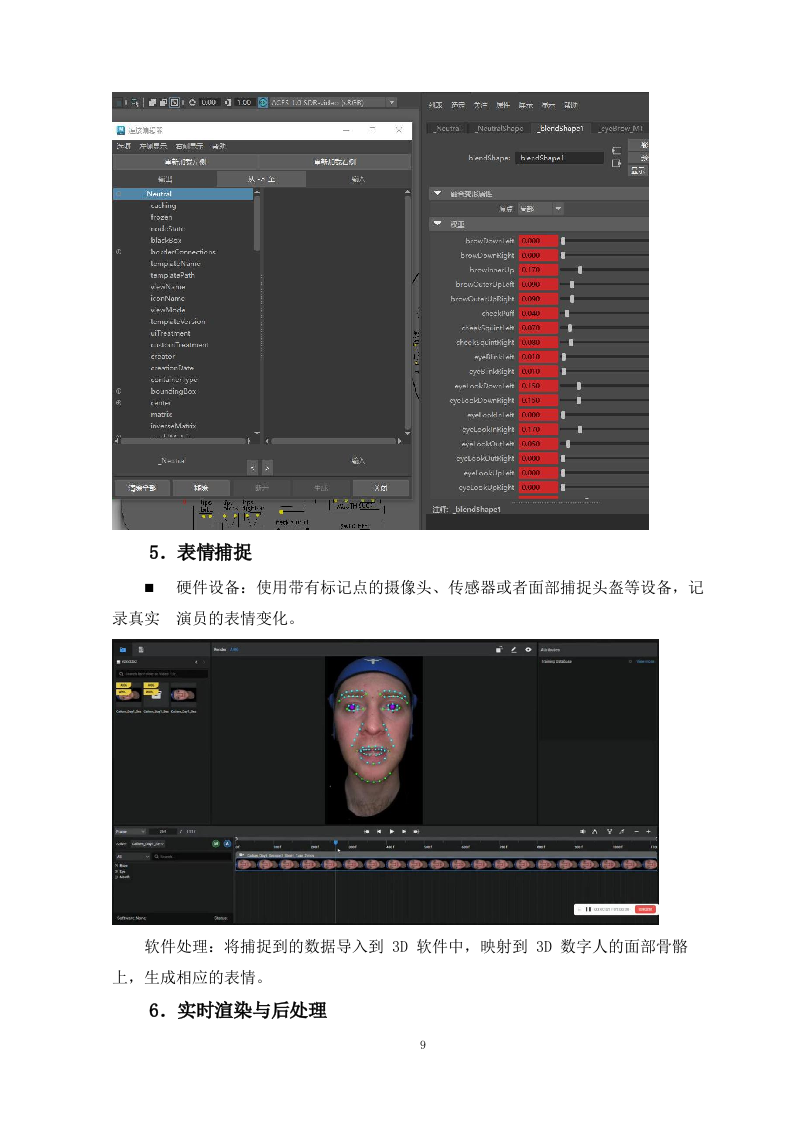
表情捕捉
硬件设备:使用带有标记点的摄像头、传感器或者面部捕捉头盔等设备,记录真实 演员的表情变化。
软件处理:将捕捉到的数据导入到
3D
软件中,映射到
3D
数字人的面部骨骼上,生
成相应的表情。
实时渲染与后处理
实时渲染:在游戏引擎
(
如
Unreal
Engine
或
Unity)
中,通过实时计算来展示
3D
数
字人的表情变化,适用于游戏、虚拟现实等实时应用。
后处理:在得到实时渲染结果后,使用美术对特定渲染角色风格而设定的参数进行微调,修正不自然的部分,增强表情的真实感。
AI 驱动算法
一些先进的技术如深度学习也被应用于表情生成,通过训练神经网络来自动识别和生成表情。利用AI算法分析文本或语音输入,自动转换成对应的表情动画,实现更自然的交互
体验。
其他配套要求
在项目期内,可根据业务运营需求,提供上述服装、表情、动作任意组合的数字人视频、GIF 文件。以下为我方数字人服装、发型、表情任意组合的示意图。
数字人能力方案
在本期项目中,针对建模好的数字人形象,需要具备如下能力:
1
、业务加载:提供适配客户机顶盒和中屏音箱安卓系统的3D数字人形象渲染
SDK
,在
机顶盒、音箱端完成侧完成动作、表情、服装的渲染,渲染后数字人互动流畅不低于
30FPS,数字人加载页面需支持透明背景。
2
、语音播报和嘴形一致:在3D数字人形象渲染
SDK
需支持接口的方式,输入要语音播
报的文字推荐话术或反馈用户的话术;通过云端完成唇形驱动的方式,在
3D
数字人形象渲
染
SDK
实现数字人唇形与数字人播报音频内容一致。我司在本期项目中将继承客户的
TTS
语音播报能力,在端侧由
3D
数字人形象渲染
SDK
进行语音播报,预先设置好语音和口型的
播放时间参数,保证播报和
3D
数字人唇形展示无延迟。
3、按需操纵数字人:3D
数字人形象渲染
SDK
需提供标准接口,客户产品在集成
3D
数
字人形象渲染
SDK
后,可以切换
3D
数字人的服装、动作、表情;可以打断
3D
数字人正在播
报的语音;可以打断计划展示的一串动作,当前动作做完后,回归待机动作。
我司
3D
端侧交互
SDK
采用
WebGL (Web Graphics Library)渲染技术。WebGL
是一种基
于
HTML5
的
API
,用于在网页浏览器中渲染高性能的
2D
和
3D
图形,而无需依赖任何插
件。
IOS/Android
分别以
WKWebView
和基于
Chromium
的
WebView
原生提供最佳的
Web
技
术支持;
PC
浏览器原生支持
WebGL
,即在
PC
、
IOS
、
Android
、
Linux
等主流系统均可适配使
用。
我司 3D 端侧交互 SDK 功能清单如下表所示:
模块
功能点
功能点详细描述
数字人配置管理
配置文件管理
骨骼文件地址:渲染出 3D 模型
动作名与具体动作映射关系:根据动作名渲染具体动作
皮肤名与具体身体部位映射关系:根据皮肤名显示对应的身体部位唤醒前的 idle 动作名列表:唤醒前随机播放其中的一个动作
唤醒后的 idle 动作名列表:唤醒后随机播放其中的一个动作
缺省的动作名列表:每个答复都应该有一个动作,如果接口没有返回, 从缺省的动作列表中选择一个播放
数字人服装管理
提供不同的服装选项,允许根据场景或主题更换数字人的服装。
数字人发型管理
提供多种发型选项,允许根据数字人的角色或个性进行选择。
动作管理
允许对数字人模型的肢体动作进行精确控制,包括但不限于行走、跳跃、
挥手等。这种控制能力使得数字人能够执行复杂和多样化的动作序列。
端侧
3D
驱动
SDK
基
础功能
组件控制
控制前端页面上的 UI 组件是否渲染
need_asr:是否需要语音识别的 UI 组件;0-不需要,1-需要
need_text:是否显示输入输出文本组件;0-不需要,1-需要
need_chat:是否需要使用标准对话接口:0-不需要,1-需要
input_text:是否需要对话文本输入组件:0-不需要,1-需要
3D 角色渲染
从配置
3D
模型配置接口获取到模型骨骼、动作、皮肤、
IDLE
等信息后,
在 UI 页面中渲染出 IP 角色,
动作渲染
默认渲染指定动作,没有返回动作时,从缺省动作中选择一个播放。动
作切换进行过渡处理
实时语音识别
实时语音识别,包括后端加密签名接口
语音识别结果回
调
输入参数为:asr 识别到的文本,形如:asr_hook(asr_text);给一个
默认的实现,将 asr_text 显示在 UI 上
对话集成
请求对话系统接口,并仅需分句/分词处理
对话结果回调
输入参数为:chat 接口的结果,形如:chat_hook(chat_response);
给一个默认的实现,将 chat 结果的文本显示在 UI 上
语音合成
对接流式 TTS 接口,获取播放的语音列表
语音合成结果回
调
请求流式
TTS
接口成功后回到,输入参数为:
tts
接口的结果,形如:
tts_hook(tts_response);此处默认实现为 null
音频播放控制
流式播放 tts 的返回结果
音频播放回调
当流式 tts 播放完完毕后调用,传入参数为空,形如:audio_hook()
端侧
3D
驱动
SDK
外
部接口
播放动作
传入动作名,SDK 渲染出对应的动作
打断动作
打断当前的动作(loop<0,为 infinite 动作)
infinite
动作:中断循环
loop
部分,播放完
end
部分;再执行后续动作
" infinite 动作:直接中断当前动作,执行后续动作
切换皮肤
传入皮肤名,sdk 渲染出对应的皮肤
调用 chat 接口
传入
c
ha
t
接口的请求体,
S
D
K
发起
c
h
a
t
请求,并执行完后续的
p
ip
e
li
n
e
调用播报接口
传入
tts
接口的请求体,
H5
发起
tts
请求,并执行完后续的
pipeline
3D 驱动服务
口型驱动推理
输入音频,输出口型参数,支持 30/60fps
交互接品
带加密的交互接口,输入文本和音色,输出音频和口型 list
部分功能详细介绍如下:
多模态交互
语音交互是数字人最常见的交互方式。收音质量是语音输入模块的重要评价标标准。收音模块包含了回音消除、噪音抑制、混响消除等算法。
除此之外,我司近期还研发了多模态语音交互,可以通过摄像头进行唇动识别,与语音降噪技术相结合,提供更好的交互体验。
唇形渲染/动作生成
blendshape 驱动口型方法
仅将语音作为驱动源。语音输入到模型,预测出blendshape系数。
Blendshape驱动支持Arkit61个blendshape、Metahuman600+blendshape标准。
音素驱动口型方法
仅将文本作为驱动源。将文本时间序列转换成音素时间序列,并输入到模型,从而预测出Viseme系数。
使用viseme驱动的方式需预先准备好每个viseme对应的面部绑定或面部动画,因此其
难以应用在较高精度的模型驱动中。
动作驱动
动作驱动包括实时动作生成及动作标签映射两种形式。动作驱动需与渲染引擎进行一定 程度的集成,以保障动作流畅度。
常见的基于对话系统的动作标签映射流程如下:
语音播报视频生成驱动
在播报视频生成的场景,小冰平台可支持两种方式
3D
资产驱动合成视频
通过
3D
驱动的视频作为训练数据,生成
1:1
的
2D
数字人
在视频呈现的效果上均可保持高度拟真、自然,在多语种驱动上,2D 的口型适配度比3D 有一定优势;
对话配置
新建机器人
用户可以通过导入或点击界面新建交互机器人。
多轮对话配置
意图管理
WEBHOOK 集成
动作配置
指定动作配置
随机动作
子句动作
图片配置
接口方案
冰数字SDK/API是套应用程序接,支持Web、安卓、iOS多个平台的数字应
用开发,方便客户将数字能集成进不同的终端与场景。您可以基于SDK或API开发,使
用冰在数字形象、内容播报、智能对话、模型等多方面的能,帮助您构建功能与体验丰富应用程序。
本产品适用于在营销推广、客户服务等场景中,期望为消费者带来全新优质体验的,并且寻求降本增效的企业,主要面对的行业包括新零售、政务、金融、运营商、传媒等,场景包括数字屏、数字短视频、数字员等。本产品可帮助企业简便高效的将数字嵌到企业自有产品中,快速上线,落地运营。
接口规范和集成方法
接口规范
小冰机器人交互平台提供标准的
Webhook
对接接口。用户可通过页面进行接口添加和配
置操作。以下为详细的接口规范:
集成方法
该接口以 Webhook 形式进行集成,使用 http 接口进行通信。
集成接口的触发方式包括闲聊兜底和自定义事件触发的方式。其中自定义事件支持语义 配置、关键词等触发方式。
端侧渲染 SDK
3D 虚拟人 SDK 说明文档
本方案提供一个
web
页面,可使用各种
webserve
在服务器或本地部署,调用方使用
iframe
加载页面,并使用
postmessage
进行相互通信。
加载虚拟人页面
使用iframe加载页面的地址形如
:https://domain/characters/{ip_name}/models/{model_name}?need_asr=1&need_text=1&need_chat=1传入给页面的参数分为两类PathParameters:
页面中调用后端接口使用的参数
ip_name:IP
角色名字,如
xyy
model_name:IP
角色的
3D
模型名,如
blue-90k
控制前端页面上的
UI
组件是否渲染
need_asr
:是否需要语音识别的
UI
组件;
0-不需要,1-需要
need_text:是否需要文本输入组件;0-不需要,1-需要
need_chat:是否需要使用标准对话接口:0-不需要,1-需要
img
: 背景图链接地址:如为空则为透明背景
虚拟人语音对话 pipeline
麦克风拾音->
asr(实时语音识别)
->
(asr_hook)->
chat
->
[chat_message
(chat_hook)->
tts
-> (tts_hook)
->音频渲染(嘴型可选) ->
(audio_hook)
->
动作渲染->
(进
入循环)麦克风拾音
asr
实时语音识别
asr_hook
:
asr识别结束后的回调,输入参数为:asr识别到的文本,形如:asr_hook(asr_text
);给一个默认的实现,将asr_text显示在UI上
chat:请求对话接口
chat_hook
: 请求
chat
接口成功后的回调,输入参数为:
chat
接口的结果,形如:
chat_hook(chat_response);给一个默认的实现,将 chat 结果的文本显示在 UI 上
tts
:请求流式
TTS
接口,获取播放的语音列表
tts_hook
: 请求流式
TTS
接口成功后回到,输入参数为:
tts
接口的结果,形如:tts_hook(tts_response);此处默认实现为 null
音频渲染:流式播放
tts
的返回结果
audio_hook
:当流式
tts
播放完完毕后调用,传入参数为空,形如:
audio_hook()
动作渲染:渲染指定动作,没有返回动作时,从缺省动作中选择一个播放
所有
hook
都以消息的形式传递给页面调用方,消息格式如下:
虚拟人页面向调用方发送消息的代码样例
const hookSDKmsg = (param: any, type: string) => { const sendmsg = {
type: type, data: param,
};
window.parent.postMessage(sendmsg);
};
模型加载渲染完成回调
hookSDKmsg('GlbLoadComplete', 'GlbLoadCompleteHook');
//data demo
{
"type": "GlbLoadCompleteHook"
}
asrhook 语音识别回调hookSDKmsg(recognizeText, 'asrHook');
//data demo
{
"type": "asrhook", "data": text
}
chathook 对话回调hookSDKmsg(res.data, 'chatHook');
//data demo
{
"type": "chatHook", "data": text
}
ttshook 语音合成回调hookSDKmsg(res, 'ttsHook');
//data demo
{
"type": "chatHook", "data": text
}
audioFinishHook 语音播放完成回调hookSDKmsg('audioFinishHook', 'audioFinishHook');
//data demo
{
"type": "audioFinishHook"
}
虚拟人文本对话 pipeline
文本输出 -> chat -> (chat_hook) -> tts -> (tts_hook) ->音频渲染(嘴型可选) -> 动作渲染 -> (进入循环)文本输入
除了将”实时语音识别”改为“文本输入”,其他与“语音对话
pip
e
lin
e
”一致
虚拟人能力调用接口
页面中同时会定义一些接口,供外部调用,外部调用时均以消息的格式传入内层页面
播放动作:传入动作名,页面渲染出对应的动作
打断动作:打断当前的动作
切换皮肤
数字人能力采购项目方案137页.docx


