











项目编号:
公共数据治理运营支撑与数据应用模型设计项目实施
技
术
方
案
目录
1
项目总体概况
6
1.1
项目背景
6
1.2
建设内容
7
1.3
建设目标
7
2
项目技术方案
9
2.1
整体方案
9
2.2
模型设计思路及规范
11
2.2.1
数据模型分层设计
11
2.2.2
数据模型分域设计
13
2.2.3
物理模型设计
15
2.2.4
逻辑模型设计
16
2.3
人口库法人库数据采集
18
2.3.1
数据采集执行过程
18
2.3.2
数据采集管理
25
2.3.3
数据源采集监控
27
2.4
人口库数据资源整合
29
2.4.1
数据整合
29
2.4.2
功能拓展
30
2.4.3
人口全息档案
31
2.4.4
人口关系图谱
53
2.4.5
人口全息视图
56
2.4.6
人口信息统计
57
2.4.7
人口信息查询
59
2.4.8
人口信息空间化
60
2.5
法人库数据资源整合
62
2.5.1
数据整合
62
2.5.2
功能扩展
64
2.5.3
法人多维画像
65
2.5.4
法人统一视图
75
2.5.5
法人信息统计
76
3
信息安全方案
78
3.1
安全原则
78
3.2
安全服务
79
3.2.1
安全集成服务
79
3.2.2
安全评估服务
79
3.2.3
等保测评支持服务
80
3.3
安全措施
80
3.3.1
网络通讯安全
80
3.3.2
安全准入
80
3.3.3
建立用户认证
81
3.3.4
项目信息数据安全
81
3.3.5
数据交换安全
82
3.3.6
操作系统安全措施
82
3.3.7
系统边界防护
82
3.3.8
防病毒系统设计
83
3.3.9
整体备份机制
83
3.3.10
应用和管理安全
84
3.3.11
程序代码安全
84
4
项目组织方案
86
4.1
项目组织
86
4.1.1
项目人力资源管理机制
86
4.1.2
项目人员组织结构
86
4.1.3
机构中人员构成与职责
87
4.2
过程管理
90
4.2.1
实施流程
90
4.2.2
项目启动阶段
91
4.2.3
需求分析阶段
92
4.2.4
需求规格阶段
92
4.2.5
设计阶段
93
4.2.6
开发阶段
93
4.2.7
测试阶段
94
4.2.8
试运行阶段
94
4.2.9
验收阶段
95
4.2.10
项目维护阶段
95
4.3
项目质量及保证措施
96
4.3.1
质量管理体系标准
96
4.3.2
质量控制过程
96
4.3.3
质量评定计划
96
4.3.4
质量管理措施
96
4.3.5
软件质量控制
97
4.4
项目风险管理
99
4.4.1
风险定义
99
4.4.2
风险管理
100
4.5
项目文档
104
4.5.1
项目技术文档
104
4.5.2
项目管理文档
104
5
项目实施方案
106
5.1
项目实施原则
106
5.2
项目实施策略
107
5.3
项目管理机制
108
5.3.1
项目进度控制
108
5.3.2
项目人员控制
109
5.3.3
项目质量控制
109
5.3.4
项目后勤保障
109
5.3.5
项目培训
110
5.4
系统安装及调试
112
5.5
系统测试
113
5.5.1
测试原则
113
5.5.2
测试目的和任务
113
5.5.3
测试的阶段
114
5.5.4
测试内容
114
5.6
系统验收及试运行
134
6
项目验收方案
136
6.1
系统验收流程
136
6.2
验收准则
136
6.3
提交技术文件
137
6.4
验收合格条件
138
6.5
验收方法
138
7
项目运维服务方案
140
7.1
运维服务承诺
140
7.2
技术支持服务方案
142
7.2.1
项目规划阶段
142
7.2.2
项目实施阶段
143
7.2.3
项目验收阶段
144
7.2.4
项目维护阶段
144
7.2.5
长期技术支持
144
7.2.6
其他技术支持
145
7.3
售后服务方案
146
7.3.1
服务机构
146
7.3.2
维护人员配备
149
7.3.3
维护工具配备
150
7.3.4
服务管理体制
151
7.3.5
售后服务方式
153
7.3.6
服务响应时间
154
7.3.7
保修期内服务
155
7.3.8
保修期后服务
155
7.3.9
应急服务响应措施
156
8
类似项目的成功案例
159
8.1
业务重点领域数据分析项目
159
8.1.1
项目目标与需求分析
159
8.1.2
业务调研咨询方案
160
8.1.3
项目成果
180
8.2
5G应用市场发展数据分析项目
180
8.2.1
项目背景与需求分析
180
8.2.2
整体思路与框架
181
8.2.3
业务研究与咨询方案
182
8.2.4
项目成果
196
项目总体概况
项目
背景
近年来,H市立足于建设卓越全球城市,率先实现政府治理能力现代化的目标,在公共数据管理和互联网政务服务方面采取了一系列改革举措,
积累了一
定的实践经验,同时也面临一些困难和问题。 根据《公共数据和一网通办管理办法》要求,需要进一步促进公共数据资源整合和利用,推进政务服务“一网通办”等电子政务发展,加快智慧政府建设,提升政府治理能力和公共服务水平。
为深入贯彻党的十九大关于建设人民满意的服务型政府的要求,坚持以人民为中心的发展思想,适应政府管理和服务现代化发展需要,深化改革,进一步优化营商环境,提升群众和企业获得感,H市通过大数据资源平台的建设,将“四大库”、“市级统建系统”、“各市级委办”、“各行政区”的数据汇聚成了市级数据湖,并以市级数据湖为基础,通过数据的集成与治理,构建了市级数据库,推动跨地区、跨层级、跨部门数据共享交换和应用,为后续公共数据的进一步整合、共享、开放提供了一定的工作基础。
建立统一的公共数据平台,全面实现H市政务“一网通办”,是贯彻党中央、国务院决策部署,深入推进“放管服”改革,持续优化营商环境,切实提升群众和企业获得感的重要举措。市委市政府已经明确,2018年建成H市政务“一网通办”总门户;到2020年,H市要形成整体协同、高效运行、精准服务、科学管理的智慧政府基本框架。
建设
内容
基于大数据资源平台,通过对“四大库”、“市级统建系统”、“各市级委办”、“各行政区”的数据等相关信息的采集、梳理、交换、整合、扩展,构建H市统一的基础信息数据库。
建设完善市级数据库:通过人口、法人、空间地理库数据源整合开发,并对接电子证照库。实现对人口、法人、空间地理信息、证照等的接入、整合、开发、利用。结合H市实际,构建公共主题库及专题库,为应用提供安全高质的专题数据服务。
通过对工商、税务、质监、民政等法人相关信息的采集、梳理、交换、整合、扩展,构建H市统一的法人基础信息数据库。
建设
目标
通过对公安、卫计、社保、民政等人口相关信息的采集、梳理、整合、扩展,构建H市统一的人口基础信息数据库。人口库以公安部门的户籍和暂住人口基础信息为基础、以身份证或护照号码以及居住性质为唯一标识,以其他部门人口信息为动态补充。
通过本次
H市大数据资源平台公共数据运营支撑项目的建设
,
完善市级数据库的建设,
将“四大库”、“市级统建系统”、“各市级委办”、“各行政区”的数据汇聚成了市级数据湖,并以市级数据湖为基础
,初步构建基础的H市大数据资源平台,实现面向各需求单位部门进行数据共享、分析和利用、以及面向社会进行数据开放的目的,支撑智慧政府的改革。
通过数据的集成与治理,构建了市级数据库,
利用
H市大数据资源平台公共数据运营支撑项
目的能力和服务,开展数据的管理、处理、分析与可视化等工作,支撑各类业务应用。
在本次项目中完成以下四个部分:
完善公共数据逻辑模型、物理模型的设计规范并确定公共数据库存储原则基层上,利用中心所建设的平台工具对进入市级数据湖的数据进行清洗、分层与转化,形成市级数据库。
完成对人口库数据资源的接入、整合、开发、利用。
完成对法人库数据资源的接入、整合、开发、利用。
本项目为构建H市大数据资源平台公共数据提供运营支撑,需要梳理并编制各部门政务信息资源目录体系,实现数据管理、交换、共享等基础功能。按照统一、集约、高效的数据开发利用理念,通过研究建立多级交换管理体系,形成政务信息资源物理分散、逻辑集中的信息共享模式,满足政府部门多方位、多层次的数据需求,为跨地域、跨部门、跨平台不同应用系统、不同数据库之间的数据交换与管理服务。
制定相关标准规范及管理制度,通过相应平台工具汇聚区内各单位公共数据及市级落地数据资源,形成区级数据池,同时经过数据清洗、转换、融合、治理后高质量的公共数据资源,形成公共数据资源中心。
项目技术方案
整体技术方案
为建设统一的数资源中心,加强数据资源整合:制定相关标准规范及管理制度,通过相应平台工具汇聚区内各单位公共数据及市级落地数据资源,形成数据池,同时经过数据清洗、转换、融合、治理后高质量的公共数据资源,形成数据资源中心。本次项目
完善公共数据逻辑模型、物理模型的设计规范并确定公共数据库存储原则基层上,利用中心所建设的平台工具对进入市级数据湖的数据进行清洗、分层与转化,形成市级数据库。并完成对人口、法人、空间地理库数据资源的整合开发,实现对人口、法人、空间地理信息的接入、整合、开发、利用,结合H市实际,构建公共主题库,为应用提供安全高质的公共数据服务。
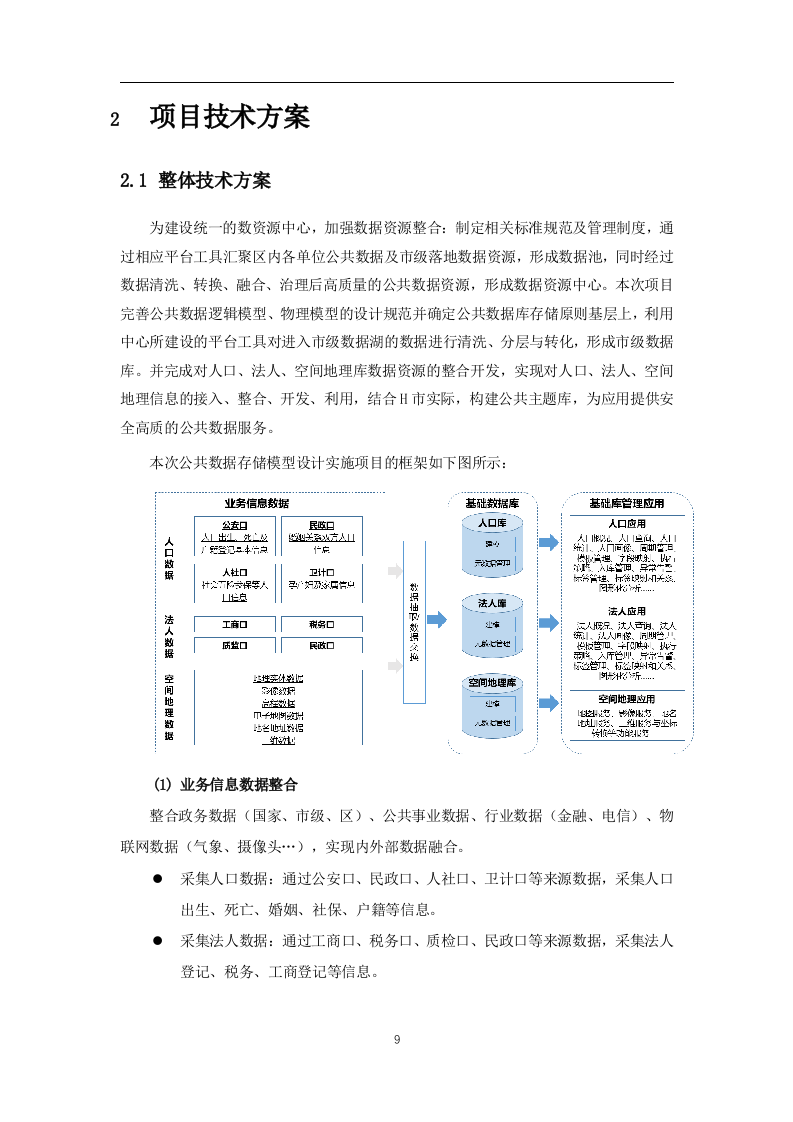
本次公共数据存储模型设计实施项目的框架如下图所示:
业务信息数据整合
整合政务数据(国家、市级、区)、公共事业数据、行业数据(金融、电信)、物联网数据(气象、摄像头…),实现内外部数据融合。
采集人口数据:通过公安口、民政口、人社口、卫计口等来源数据,采集人口出生、死亡、婚姻、社保、户籍等信息。
采集法人数据:通过工商口、税务口、质检口、民政口等来源数据,采集法人登记、税务、工商登记等信息。
采集空间地理数据:采集地图、街道、区域、小区、楼宇、景点等地名、类型、经纬度等信息。
数据抽取/数据交换
数据采集模块采用集中化多租户ETL平台进行数据采集、转换、稽核工作,完成数据标准化、集中化,实现数据脉络化、关系化,实现统一的数据处理加工,包括:离线采集、实时采集、准实时采集、流媒体采集、数据导入上报。
基础库
按照人、地、事、物、组织等对象方式对数据进行建模,形成全区统一共用的基础数据库。典型的基础数据库包括人口库、法人库、空间地理信息库。
人口库:构建全市统一的、以公民身份号位为唯一标识的、可共享的综合人口信息资源库。基于综合人口库,实现全市人口信息的汇聚治理、共享交换和应用服务,为开展跨部门、跨业务、跨区域的人口应用服务和数据共享,以及人口大数据分析、辅助决策等,提供全方位的人口信息支撑。
法人库:促进相关部门有关法人单位业务信息的关联汇聚,丰富法人单位信息资源。支撑法人单位信息资源的分布查询和深化应用。通过公共数据开放网站,分级、分类安全有序开放综合法人信息,促进社会化创新应用。
空间地理库:基于规划、国土资源等部门提供的GIS地图服务基础上,构建自然资源和空间地理基础信息,并将遥感影像、地址数据、政务信息图层等,与人口信息、法人单位、宏观经济、社会信用进行整合,形成本市空间地理基础信息资源库,为全市政府部门和企事业单位提供统一的地理空间信息服务。
模型
设计
思路及规范
数据模型分层设计
对数据
模型
进行分层能对
管理
数据有一个更加清晰的掌控,主要有
体现
清晰数据结构
、
数据血缘追踪
、
减少重复开发
、
复杂问题简单化
、
屏蔽原始数据异常
、
屏蔽业务的影响
。
每个数据分层都有它的作用域,在使用表的时候能更方便地定位和理解
。
规范数据分层,
开发一些通用的中间层数据,能够减少极大的重复计算。便于
维护数据的准确。
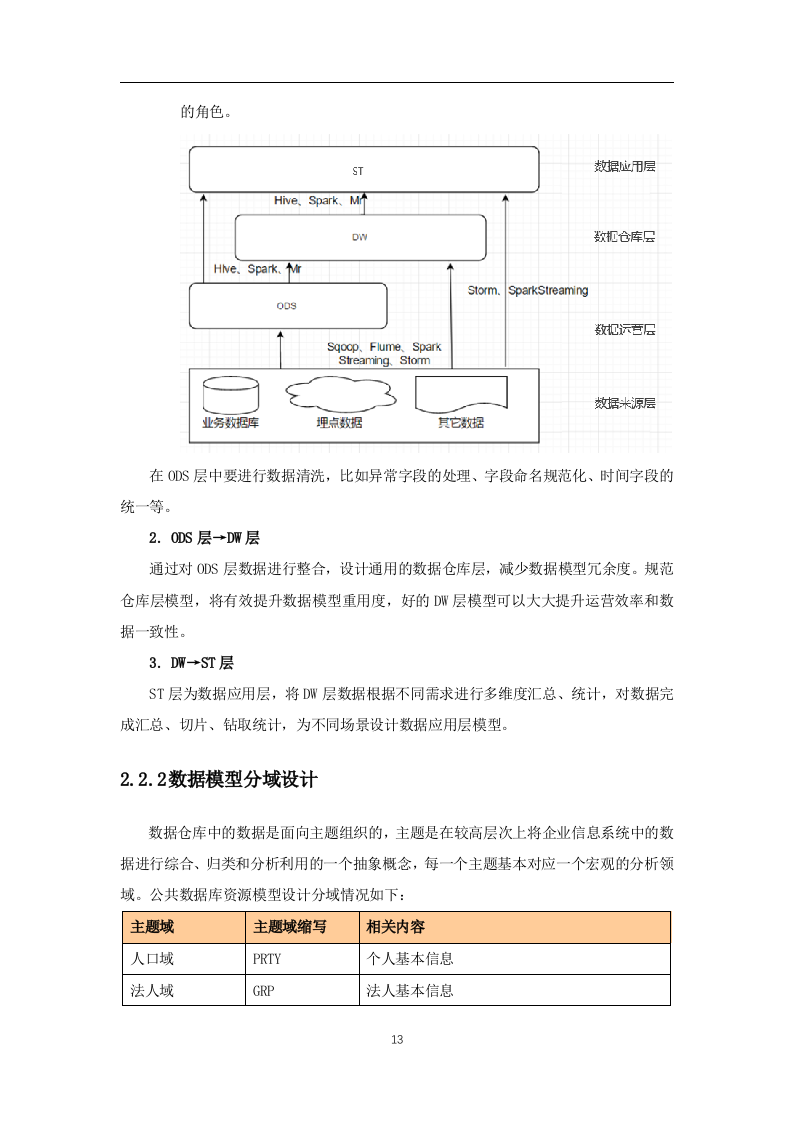
本次建设公共数据模型从层次上分为ODS、DW与ST层,即:数据运营层、数据仓库层和数据应用层。
ODS层数据为近源层数据,
数据源中的数据,经过ETL抽取、洗净、传输之后,装入本层。在源数据装入这一层时,要进行诸如去噪、去重、提脏、业务提取、单位统一、砍字段、业务判别等多项工作。
DW层数据为数据仓库层数据,ODS层数据经过整合,针对不同实体进行汇总后的数据进入该层。
ST层为数据应用层,数据更灵活,更贴近实际应用,用于数据展现。
1. 数据来源层
→
ODS层
数据主要会有两个大的来源:
业务库,使用sqoop来抽取,每天定时抽取一次。在实时方面,考虑用canal监听mysql的binlog,实时接入。
埋点日志,线上系统会打入各种日志,日志以文件的形式保存,选择用flume定时抽取,
或
spark streaming
、
storm来实时接入,kafka也会是一个关键的角色。
在
ODS
层
中要
进行数据清洗,比如异常字段的处理、字段命名规范化、时间字段的统一等
。
2
. ODS层
→
DW层
通过对ODS层数据进行整合,设计通用的数据仓库层,减少数据模型冗余度。规范仓库层模型,将有效提升数据模型重用度,好的DW层模型可以大大提升运营效率和数据一致性。
3
. DW
→ST
层
S
T
层为数据应用层,将DW层数据根据不同需求进行多维度汇总、统计,对数据完成汇总、切片、钻取统计,为不同场景设计数据应用层模型。
数据模型分域设计
数据仓库中的数据是面向主题组织的,主题是在较高层次上将企业信息系统中的数据进行综合、归类和分析利用的一个抽象概念,每一个主题基本对应一个宏观的分析领域。公共数据库资源模型设计分域情况如下:
主题域
主题域缩写
相关内容
人口域
PRTY
个人基本信息
法人域
GRP
法人基本信息
事件域
EVT
出生、死亡、诉讼
资源域
RES
空间资源、服务资源、公共资源、网络资源
账务域
ACC
消费记录、纳税记录
关系域
REL
就职记录、婚姻关系
根据对人口、法人、空间地理库数据信息
的特征
,将对人口、法人、空间地理结合H市实际,构建数据模型三大公共主题域,为应用提供安全高质的公共数据服务。
人口主题
域:
收集城市各职能局的业务数据,对数据进行清洗、比对、关联,获得人口空间数据,建立人口库数据资源。
法人主题
域:
收集城市各职能局的业务数据,对数据进行清洗、比对、关联,获得法人空间数据,建立法人库数据资源。
资源主题域:通过收集城市各职能局的空间地理资源,结合业务数据,对数据进行清洗、比对、关联,获得空间地理数据,建立空间地理库数据资源。
主题域通常是联系较为紧密的数据主题的集合。可以根据业务的关注点,将这些数据主题划分到不同的主题域
(也说是对某个主题进行分析后确定的主题的边界。)
模型
设计示例如下:
物理模型设计
依据数据仓库建模理论,结合实际经验,
物理模型设计时需确定数据模型在分布式系统中的存储形态,综合考虑
Hadoop
、MPP、一体
机
数据库、内存数据库四种形态各自特点,结合数据按照粒度不同、周期不同、主题不同形成的数据热度,制定数据的存储分布
。
分表规则
根据情况,将公共数据模型按照如下规则进行设计:
表命名
类型名称
说明
YYYYMMDD
日表
存放当天数据
YYYYMM
月表
存放月末数据,或当月累计数据
DM
多周期日表
存放多个周期的日数据
DM_YYYYMM
多周期日表累计的月表
存放多个周期的日数据,每月分表
DM_YYYY
多周期日表累计的年表
存放多个周期的日数据,每年分表
MM
多周期月表
存放多个周期的月数据
DS
当周期表
当周期最新的数据
DT_YYYYMMDD
累计日表
当月累计数据
表命名规则
基于分主题分层的原则命名:层_主题域_表名_表类型_分表规则
例如:
人口表
DWD_PRTY
_
INDIV_YYYYMMDD
法人表
DWD_PRTY_GRP_YYYYMMDD
字段命名
原
则
为了保证数据定义和数据自身质量,以提高处理效率,字段设计建议遵循以下原则:
相同字段设计命名一致性,对于多个表均有的字段,设计为统一的名称
对于表间关联常用的字段,各表应该设计成同样的字段类型。
避免对Hash键值字段进行数据的处理。
字段名称
字段命名
字段类型
枚举值
个人姓名
INDIV_NAME
VARCHAR(32)
个人证件号码
INDIV_CERT_CODE
VARCHAR(32)
个人证件类型
INDIV_CERT_TYPE
INT
0身份证;1工商登记证;10港澳居民来往内地通行证;11台胞;12外籍人士;13个体工商户营业执照;14聚类;15特殊客户;3军人证;5企业代码证;9单位证明;99其它证件
个人证件地址
INDIV_CERT_ADDRESS
VARCHAR(256)
数据
处理原则
对于数据加工处理,应该尽量在小表内进行,对于局部的数据加工处理为了不影响基础大表,应建立临时表作为工作空间。
对于年汇总、月汇总等粗粒度类数据汇总处理,应该在基于事先建立的日汇总等低粒度结果(包括用户、产品等维度上汇总)基础上进行,这种处理可减少上级统计对明细层数据的重复性读取。
逻辑
模型设计
逻辑模型设计是对概念模型设计的进一步细化,根据数据的产生频率及访问频率等因素综合考虑,确定数据热度和数据关系等规则。作为概念模型到物理模型转换的中间过程,逻辑模型设计时兼顾业务理解和系统实现。
数据
有效性策略
模型中设计的字段属性都应是具有分析价值的,对于无效性字段属性,应予以裁剪:
剔除:对源系统提供的仅用作生产使用,无分析价值的字段属性进行剔除;对源系统中的无效字段(如全为空值、全为Z等)进行剔除。
合并:对内容重复,同名异义、同义异名、同名同义不同值、反复存储的字段信息进行归并。
数据
关系定义
概念模型设计的字段属性,与源系统相应实体的字段属性存在一定的映射关系,在逻辑模型设计时,应建立与源系统字段定义间的映射关系定义。通常的映射关系有:
源系统单张表,在概念模型设计时也为单个模型的,应针对概念模型中每个字段,建立其对应的源系统字段属性映射;
源系统多表,在概念模型设计时合并为单个模型,需要针对每个数据源表与当前模型分别映射,且每个模型的每个字段属性都应有相应的映射关系;
源系统单张表,在概念模型设计时拆分为多个模型,需将每个模型与源系统的标进行分别映射,且每个模型的每个字段属性都应有相应的映射关系。
维值定义规则
统一采用维表方式定义静态的维值,例如证件类型,用户状态等字段。
维值
维值名称
枚举值
枚举值中文
生效时间
失效时间
CERT_TYPE
证件类型
0
身份证
1900/1/1
2099/1/1
CERT_TYPE
证件类型
1
工商登记证
1900/1/1
2099/1/1
CERT_TYPE
证件类型
10
港澳居民来往内地通行证
1900/1/1
2099/1/1
CERT_TYPE
证件类型
11
台胞
1900/1/1
2099/1/1
CERT_TYPE
证件类型
12
外籍人士
1900/1/1
2099/1/1
CERT_TYPE
证件类型
13
个体工商户营业执照
1900/1/1
2099/1/1
CERT_TYPE
证件类型
14
聚类
1900/1/1
2099/1/1
CERT_TYPE
证件类型
15
特殊客户
1900/1/1
2099/1/1
CERT_TYPE
证件类型
3
军人证
1900/1/1
2099/1/1
CERT_TYPE
证件类型
5
企业代码证
1900/1/1
2099/1/1
CERT_TYPE
证件类型
9
单位证明
1900/1/1
2099/1/1
CERT_TYPE
证件类型
99
其它证件
1900/1/1
2099/1/1
人口库法人库数据采集
数据采集执行过程
本项目需采集的数据分为两部分,数据湖中的人口数据和法人数据。
数据采集方式有两种:
通过数据数据湖中的数据需要经过一系列治理后,形成高质量的数据入库。
通过各部门政务应用系统与数据资源池的直接双向交互,无需通过数据湖进行中转,通过平台的调度引擎可进行交换链路的灵活设置。
抽取流程如下图:
为适应
大
数据中心多类型数据源采集的需要,
事件数据
需支持多种类型的数据采集方式,数据采集
可采用
多种丰富的数据源接口,包括:
常用标准协议接口如Socket等
FTP文件接口
JDBC/ODBC接口
消息队列(
KAFKA
)接口
Hadoop生态圈的开源技术Flume
数据抽取方式
数据抽取主要采用自动采集的方式,支持全量抽取和增量抽取。
全量抽取:数据湖或源系统的某个数据表或文件,全量进行抽取。
条件抽取:数据湖或源系统的某个数据表或文件,可根据预设条件进行数据抽取
增量抽取:监测数据湖或源系统的某个数据表或文件,仅针对增量部分进行抽取。
源数据库支持如下三种方式,根据需要进行抽取:
文件
数据库
流数据
市级数据湖归集的数据处理办法:
批数据处理:
各类批数据通过数据采集功能进入数据支撑平台,经过存储、清洗、汇总和关联汇总等,产生应用数据,并实现数据共享或开放。
流数据处理:
流数据通过数据采集功能进入数据支撑平台后,根据不同需求,可实现实时数据计算后的开放,也可实现通过实时数据分析后汇总产生应用数据,进而实现数据共享或开放。
自动入库
从数据湖和特殊应用的数据库自动采集法人数据,使用中间数据库的方式接收源端(数据湖等)按照要求提供的数据,当系统时钟到预设的自动读取中间数据库时间时,计算机自动读取中间数据库中的数据,也可以手工启动读取数据。调度可设置前置条件及时间调度方式,自动入库时间调度方式:
每月
每日
每小时
如遇到采集失败或前置时间不满足,则设置不同优先级的轮询方式:
高优先级:10分钟轮询一次,最长36小时
中优先级:30分钟轮询一次,最长24小时
低优先级:60分钟轮询一次,最长24小时
全量抽取
对采集的数据进行全量抽取,不设置抽取条件,全量抽取源表数据。能够在系统初始化时,将数据湖和其他应用中已有的信息数据全部抽取到本系统,建立汇聚库的初始化原始数据。
条件抽取
对采集的数据进行条件抽取,配置抽取条件,抽取源表数据中符合条件的数据。配置后,可按照小时、日、月自动抽取入库。
条件设置
可以设置原子条件,比如,抽取创建时间为当日的数据。
条件组合
可以将原子条件进行逻辑组合,例如:同时符合条件A、条件B的数据。
增量检查
增量抽取可以有效减少数据抽取的数量,减少对源数据库的压力,避免影响现有业务,提高数据抽取效率。以下方法可以实现准确快速的捕获变化的数据,进行增量抽取。
增量数据抽取中
有多种方式支持增量检查的
方法有以下几种:
1、触发器方式
触发器方式是普遍采取的一种增量抽取机制。该方式是根据抽取要求,在要被抽取的源表上建立插入、修改、删除
3个触发器,每当源表中的数据发生变化,就被相 应的触发器将变化的数据写入一个增量日志表,ETL的增量抽取则是从增量日志表中而不是直接在源表中抽取数据,同时增量日志表中抽取过的数据要及时被标记 或删除。
为了简单起见,增量日志表一般不存储增量数据的所有字段信息,而只是存储源表名称、更新的关键字值和更新操作类型
(insert、update或 delete),ETL增量抽取进程首先根据源表名称和更新的关键字值,从源表中提取对应的完整记录,再根据更新操作类型,对目标表进行相应的处理。
对从数据湖和其他应用中抽取的信息数据进行增量检查或时间戳比对,并对增量数据进行标记,以方便增量抽取。
2、时间戳方式
时间戳方式是指增量抽取时,抽取进程通过比较系统时间与抽取源表的时间戳字段的值来决定抽取哪些数据。这种方式需要在源表上增加一个时间戳字段,系统中更新修改表数据的时候,同时修改时间戳字段的值。
有的数据库
(例如Sql Server)的时间戳支持自动更新,即表的其它字段的数据发生改变时,时间戳字段的值会被自动更新为记录改变的时刻。在这种情况下,进行ETL实施时就 只需要在源表加上时间戳字段就可以了。对于不支持时间戳自动更新的数据库,这就要求业务系统在更新业务数据时,通过编程的方式手工更新时间戳字段。
使用时间戳方式可以正常捕获源表的插入和更新操作,但对于删除操作则无能为力,需要结合其它机制才能完成。
3、全表比对方式
全表比对即在增量抽取时,
ETL进程逐条比较源表和目标表的记录,将新增和修改的记录读取出来。
优化之后的全部比对方式是采用
MD5校验码,需要事先为要抽取的表建立一个结构类似的MD5临时表,该临时表记录源表的主键值以及根据源表所有字段的数据 计算出来的MD5校验码,每次进行数据抽取时,对源表和MD5临时表进行MD5校验码的比对,如有不同,进行update操作:如目标表没有存在该主键 值,表示该记录还没有,则进行insert操作。然后,还需要对在源表中已不存在而目标表仍保留的主键值,执行delete操作。
4、日志表方式
对于建立了业务系统的生产数据库,可以在数据库中创建业务日志表,当特定需要监控的业务数据发生变化时,由相应的业务系统程序模块来更新维护日志表内容。增量抽取时,通过读日志表数据决定加载哪些数据及如何加载。日志表的维护需要由业务系统程序用代码来完成。
5、
系统日志分析方式
该方式通过分析数据库自身的日志来判断变化的数据。关系犁数据库系统都会将所有的
DML操作存储在日志文件中,以实现数据库的备份和还原功能。ETL增量 抽取进程通过对数据库的日志进行分析,提取对相关源表在特定时间后发生的DML操作信息,就可以得知自上次抽取时刻以来该表的数据变化情况,从而指导增量 抽取动作。
有些数据库系统提供了访问日志的专用的程序包
(例如Oracle的LogMiner),使数据库日志的分析工作得到大大简化。
增量抽取
能够在监控到数据湖和其他应用的数据库的数据更新后,从库中抽取更新的基础数据。
捕获变化数据,仅对自上次导出之后变化数据(增、删、改)进行抽取
,并对更新的数据进行增量检查和增量抽取。增量抽取后,进行基础表更新。
对捕获
增量的
方法有两点要求
1
、
准确
2
、
不要对业务系统造成太大压力
数据校验
支持系统自动校验和人工校验方式。
自动校验:
针对每个抽取配置可以设置自动校验规则。系统自动对采集的数据进行数据项完整性、数据值合理性、合法性、有效性、规范性、一致性、正确性等一系列检查和处理。对采集的数据一般采用系统自动校验方式进行校验。
自动校验规则可配置:
条数阈值检查
空值数量阈值检查
日期等其他自定义规则检查
人工校验:
采用人工的方式对采集的数据进行格式、编码、内容方面的校验等的检查和处理。一般是对重要的数据或自动校验出现异常的情况采用人工校验。
入库处理
能对完成抽取和校验的数据进行解析和处理,对多余的重复的信息进行清洗,并自动存入综合信息资源原始库中,为信息资源整合提供较好的数据基础。
多进程抽取:针对源数据较大的,设置分区,进行多进程同时抽取,可提高抽取效率。
分区处理:针对大表进行合理分区,入库后进行分区、合并、建立视图等方式,提高源表的使用效率。
数据转换:对日期、时间、证件号码等字段进行转换,使其符合统一的标准。
将数据转换为指定格式并进行数据清洗保证数据质量。
公共数据治理运营项目实施技术方案(196页).docx


